Agones はゲームサーバーをKubernetesで管理するための機能を提供するフレームワークである。Agonesについては過去の記事で取り上げているので詳細はそちらを参照。
- Agones は何であって、何でないか - castaneaiのブログ
- Agones はなぜ、どのようにPodへの直接接続を実現しているか - castaneaiのブログ
- Agones のインフラコストを抑える工夫 - castaneaiのブログ
Allocate(割り当て)とスケール
Agonesではゲームセッションに利用するサーバーを事前に割り当て(Allocate)する必要がある。 GameServerAllocationというKubernetesリソースを作成するか、Allocator ServiceにgRPCで要求することで割り当てができる。
小規模なサービスであれば欲しいときに割り当てをする、それだけで十分動くが 大規模・高頻度な割り当ての実現には工夫が必要だ。

Agonesのゲームサーバー(以下GSと略する)は Ready, Allocated といった状態を持つ。 Allocateを要求するとReady状態のGSを探して割り当てる。割り当てられたGSは Allocated 状態に変わる。 よって、多量のAllocateをさばくにはReady状態のGSが常に余るようなスケールが必要となる。 そのためにFleetAutoscaler等が用意されている。
しかし、スケールといっても限度がある。上の図が示すようにGSはNodeの中に配置されるため、次々とReady状態のGSを増やすためにはNodeも合わせて増やす必要がある。 あまりに高頻度な割り当てが続くと、GSやNodeの追加が追いつかないか、仮に追いついたとしても相当数のPod, Nodeが作られインフラコストが非常に高くなる。
Allocatedの再利用 (High Density GameServers)
多量の割り当てを助けてくれるやり方のひとつが、Allocated GSの再利用だ。 High Density GameServers と呼ばれているこのやり方はAgonesのドキュメントにも記述がある。
High Density GameServers | Agones
具体的なやり方はこのドキュメント通りなので、詳細は省くが大まかに書くと次の通り。
- AllocatedになったGSを再利用して複数個のゲームセッションを詰め込む
- 割り当て要求に条件をつける
- ラベル
availableがtrue - 状態はReadyとAllocatedどちらでもOK
- ラベル
- 割り当てと同時にGSに ラベル
available: falseを設定 - GS内では割り当てイベントを監視し、引き続き割り当てを受け入れ可能であればラベル
available: trueを設定
KubernetesのLabelを使ってロックを取るような挙動なので、Label locking methodと呼ばれてたりする1。
Label locking methodを実装
上記のLabel locking methodを持つ最小限のGSをGoで書いてみた。 新たな割り当て(Allocate)を検知したらLabelをもとに戻してロックを解除する、を繰り返すような実装だ。
Agones high density GameServer example with label locking method. · GitHub
高速なAllocateをさばく
Label locking methodを使った場合、どれくらいの割り当て速度が出るのか。 AllocatorとGS間でLabelの変更が反映される時間はKubernetesクラスターの性能や負荷によって変わるが、最大1秒ぐらいかかるとみておくとよいらしい。
Agones, and Kubernetes itself are built as eventually consistent, self-healing systems. To that end, it is worth noting that there may be minor delays between each of the operations in the above flow. For example, depending on the cluster load, it may take up to a second for an SDK driven label change on a GameServer record to be visible to the Agones allocation system. We recommend building your integrations with Agones with this in mind.
引用元:https://agones.dev/site/docs/integration-patterns/high-density-gameservers/#consistency
実環境でどのくらいの速度が出るのか、Google CloudのマネージドKubernetesを使って実験した。
- Cluster: GKE Autopilot (Region: asia-northeast1)
- Agones v1.36.0
- GS: 1 Pod
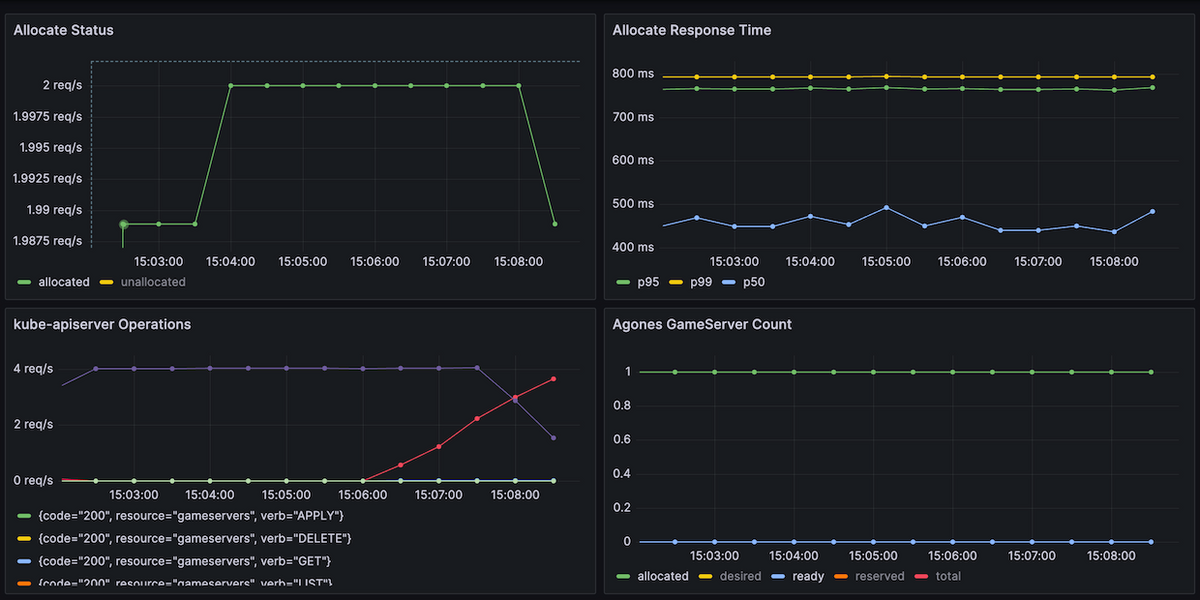
結果は上の画像の通りで、約2 allocate/s で処理されたことがわかる。 もしLabelの反映に1秒かかるのなら1 allocate/sしか出ないはずだから、それよりは速く処理できている。(1 / 2.0) = 約500msといったところか。
GS数の調整
ただ、現実的にGSが1個だけということはないと思うので、GSの数を10に増やしてみる。

すると、約20 allocate/sという結果になった。 つまり GSの数に比例してAllocate速度も上がる。 あるGSがLabelによってロックされている間でも、他にロックされてないGSが余っていればそちらを使えるからだ。 GSの数が増えれば増えるほどその余裕が生まれやすい。 ざっくり計算すると N allocate/s を目指すならGSを約0.5N Pod用意すればよい ことになる。
batchWaitTime の調整
また、Agonesのドキュメントを探っているとAllocateに影響するパラメータとして batchWaitTime というものがあることを知った。
agones.allocator.allocationBatchWaitTimeWait time between each allocation batch when performing allocations in allocator mode
引用元: Install Agones using Helm | Agones
割り当て処理を行うAgones AllocatorはKubernetes Control planeに反映する前に内部でバッチ的にリクエストをまとめている部分があり、そこに待ち時間が設定されているようだ。デフォルトは 500ms だが、「batchWaitTimeを小さくするとAllocate性能が改善する」という報告がある。
Make batchWaitTime configurable in the Allocator · Issue #2586 · googleforgames/agones · GitHub
ソースコードのコメントを読む感じ、AllocatorのCPU使用率やControl Plane (etcd)への負荷を抑える目的のようだが、GKEのMetricsを見ているとControl Planeは余裕があるので、試しにbatchWaitTimeを 2ms まで下げてみた。
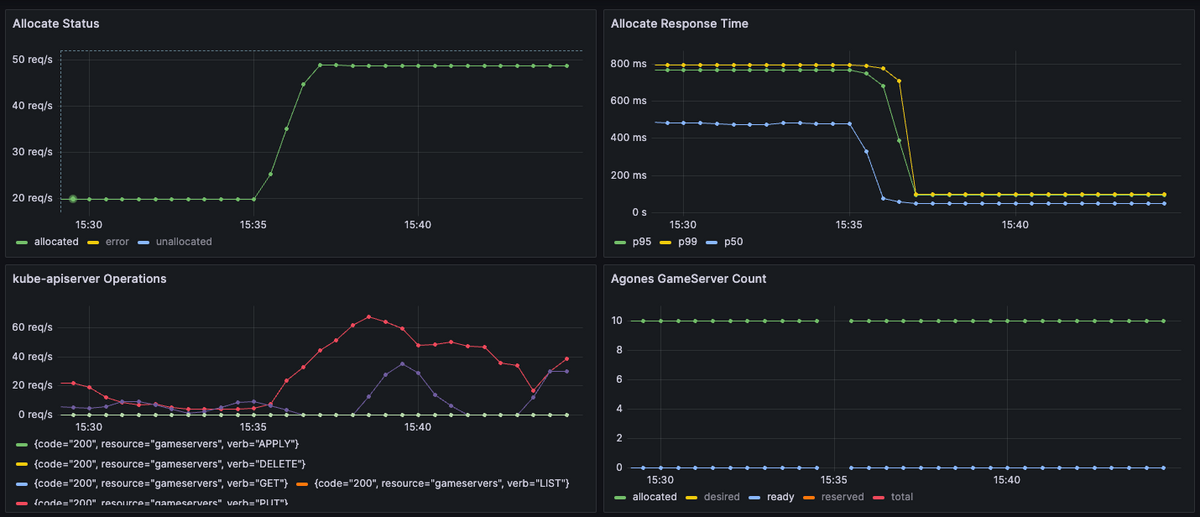
すると 約 50 allocate/s と2倍以上の性能向上が見られた! 1 Allocateあたりのレスポンス時間も中央値 (50 percentile) が 500ms から 50ms と大幅に改善された。 その分、Kubernetes Control Planeへのリクエスト数とAllocatorのCPU使用率が倍増したが、Control Planeが耐えられるならばbatchWaitTimeを下げられるところまで下げてしまって良さそうだ。同時にAgones AllocatorのCPU使用率も上がるので、resource requestsの見直しも忘れずに。
batchWaitTime: 2ms の前提で再計算すると、1 allocateあたり 200ms で処理できることになり、 N allocate/s 目標であれば GSを 0.2 N Pods 用意すればよい、となる。
ただし、この実験は割り当てのラベルをON/OFFするのみの実装なので、現実世界のゲームサーバーではより複雑となる。 この実装だと1つのGS内に無際限にセッションが作られ続けてしまうので、現実的には最大収容数などを見てLabelのロックをかけることになる。 そうなると、収容可能なGSがない場合、FleetAutoscalerなどでPod自体をスケールする必要がでてくる。 より現実に即した場合Allocate速度が落ちることも十分考えられる。事前に最大のユーザー数を見積もって負荷試験をするのが確実である。
再割り当て可能になるまでの時間を減らせるか?
一度割り当てたGSが再度割当可能になるまでGKE Autopilotでは約200msかかっていた。 ここが短くなればより少ないGS数でAllocate要求を処理できそうだが、それは可能か?
Labelの情報伝播速度を上げるということは、Kubernetes Control Plane(もっと言えば etcd)の性能を上げることにつながる。 しかし、GKEのようにControl Planeがマネージドになっているサービスではそこを直接変更するのは難しそう。
他の選択肢
あまりに大規模なゲームや急激なアクセスが予想されるサービスでは、N allocate/s に対して 0.2 N Podsを用意するのが難しい場合もある。 たとえば毎秒10000回のマッチングが成立するような大人気ゲームだと 0.2 * 10000 = 2000 GSが必要だ。 2000 Podにもなるとインフラコストも多大にかかる上に、Kubernetesのクラスターに対するあらゆるオペレーション(新バージョンのデプロイ等)が現実に耐えるものになるか怪しい。
考えられる対策としては
- 連続するAllocate requestをバッチ的にまとめ、1つのAllocate requestで処理する
- 事前にAllocatedされたプールを用意しておき、そこから再利用する仕組みを実装する
- Agones Allocatorを使わず、自前でGSの管理をする
- クラスターを複数に分けて運用する
などが考えられるが、どれもメリット・デメリットはある。
私見だが、このようなワークロードをKubernetes Control Plane (etcd)でやるべきではないとも感じる。 Control Planeはインフラ管理者が見るためのPodやNode等を管理している場所だ。 そこにユーザーアクセスに応じて高頻度で読み書きするデータを混ぜるのはよくない気がする…という理由である。
一定以上の負荷になればKubernetes Control Planeではなく何か別のDBなどを利用するほうが合理的に感じる。 とはいっても、Agonesが持つGS管理の機能を一部再発明することになるため、Agones Allocatorで十分さばける規模であればAgonesに頼ったほうが保守は容易だろう。