Agones はゲームサーバーをKubernetesで管理するための機能を提供するフレームワークである。Agonesについては過去の記事で取り上げているので詳細はそちらを参照。
Agones の GameServer も内部的には Kubernetes Pod でありその数が多いほどインフラコストがかかる。 よってその時で使っている分だけを上手く確保してインフラコストを抑えたい。
Kubernetes の世界では HPA (Horizontal Pod Autoscaler) や Cluster Autoscaler によって負荷に応じて動的にリソースを増減できる。 では、 Agones においても同様に動的なリソース増減ができるのか?その方法と考慮事項を探っていく。
Fleet Autoscaler を使った最適化
まず Kubernetes の汎用的なHPA (Horizontal Pod Autoscaler) は Agones では 使えない。 HPAは主にCPU使用率が低いPodを減らすことでリソース削減を行うが、Agones GameServer は CPU使用率が低い=不要なサーバーとは限らないからだ。 CPU使用率が低くてもゲームは進行中かもしれない。
そこで、Deployment と HPA の代わりにAgonesは Fleet と Fleet Autoscaler を提供する。
Fleet
Fleet は Kubernetes Deployment のようなもので、特定 Image のゲームサーバーを複数個並べる定義ができる。
# Fleet 定義の例(一部) apiVersion: "agones.dev/v1" kind: Fleet metadata: name: fleet-example spec: replicas: 2 scheduling: Packed ...
Deployment と似ているが、スケールダウン時に使用中のGameServerを保護する機能や、 新たにPodを配置するとき既にGameServerが多く乗っているNodeに優先して配置してくれる1機能が提供される。
Fleet Autoscaler
そして Fleet replicas を動的に増減してくれるのが Fleet Autoscaler である。 ドキュメント 通り、Buffer policy と Webhook policy がある。
たとえば Buffer policy では常に N個のGameServer はReady(準備完了)であるべき、という指定ができる。 その指定を満たす範囲内で Fleet 内の GameServer の数が動的に増減する。
apiVersion: "autoscaling.agones.dev/v1" kind: FleetAutoscaler metadata: name: fleet-autoscaler-example spec: fleetName: fleet-example policy: type: Buffer buffer: bufferSize: 5 minReplicas: 10 maxReplicas: 20
よって、ゲームのアクセス規模や頻度に合わせた適切な設定の Fleet Autoscaler を使うと GameServerは使用量に応じて増減され無駄なくリソースが使われインフラコストは最適化される。
Cluster Autoscaler を使った最適化
Fleet Autoscaler により GameServer の数は動的に増減されるので一見それでインフラコスト問題は解決するかのように見える。 しかし、そう上手くいかない場合もある。 Cluster Autoscaler の例とともに紹介する。
前提として、Fleet はデフォルトで 「できるだけ少ないNodeにGameServerを詰め込む」 動きをする。 これは Packed scheduling と呼ばれる。 Fleet Autoscaler によって GameServer が削減されるときも Packed scheduling が働いて GameServer が少ない Node から優先的に削除される2。
たとえば次のように 1 Node に 3 GS (GameServer) が配置可能で、3 Nodes, 7 GS が存在する環境を想定する。 ここで Fleet Autoscaler によって1つのGSを削減しようとすると GSの数が最も少ない Node 3 から順にスケールダウンされていく。

そして、空になった Node は削除される。 この Node の増減をやってくれるのが Cluster Autoscaler である。 こうやって不要な Node は削減されインフラコストも削減できる。

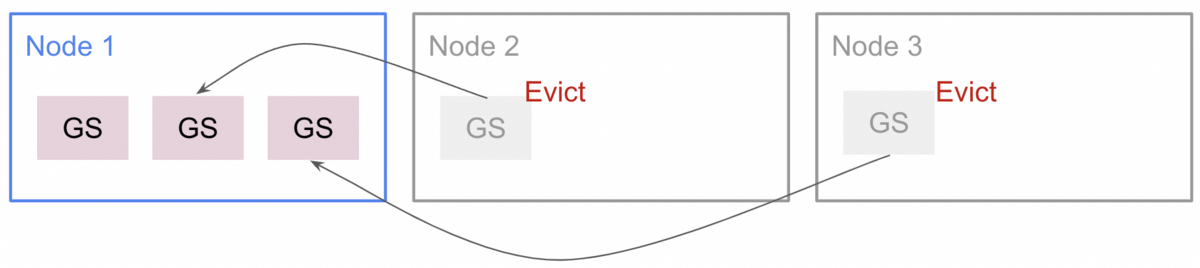
では、次の図の場合はどうだろうか? 全Node に乗っているGSの数が同じだと、どこが最も少ないかという判断ができない3。

ここで一気に3つのGSを減らすと 3つのNodeからランダムに削除対象が選ばれ削除後も全Node同じGS数になる可能性がある。

それが繰り返されると次のように全Nodeに1GSずつが残り、リソース効率が悪い(インフラコストも無駄に高い)配置となる。

このケースに限らず、Packed scheduling は常に完璧な配置をしてくれる保証はない。best-effort な印象である。 このような状況下では Cluster Autoscaler は動いているGSを別のNodeへ移動させようとする。 動いているPodを追い出し(Eviction)、別のNodeで再起動させる流れとなる。
通常の Kubernetes Pod であれば上手く機能するが、Agones の場合中断されると困るときもある。 Fleet Autoscaler のように「使用中(Allocated)」のGameServerは除外すればいいのでは?と思うところだが、 Cluster Autoscaler は Kubernetes コアの機能であり、Agones の内部事情までは考えてくれないのである。
そうした背景から従来の Agones では Evict を阻止する指定("cluster-autoscaler.kubernetes.io/safe-to-evict": "false")がされていた。
これが原因でリソース効率が悪くなりインフラコストが削減できない可能性がある。
そこで、Agonesの最近のバージョンでは SafeToEvict という機能が導入された。 詳しい解説はドキュメントのControlling Disruption にあるため ここでは Cluster Autoscaler と関わる部分のみ軽く紹介する。
- この機能は現状 Alpha なので利用するには Feature Gate の設定が必要
- ゲームがいつ中断命令が来てもM分以内に終了できる仕様であれば、Cluster Autoscaler による Evict を許可できる
GameServer.spec.eviction.safe: Alwaysを指定すると Evict を許可できる- M分というのはKubernetesの環境によって異なる(GKE は 10分)
- サーバーの実装に SIGTERM のハンドリングが必要
- Pod の
terminationGracePeriodSecondsを M分以内に設定
今後は中断耐性のあるゲームであれば、この SafeToEvict 機能を使ってさらなるインフラコストの圧縮が期待できる。
ゾンビサーバーへの対処
Agones の GameServer をこれからゲームに使う用に確保(Allocate)したが、後片付けが行われず無駄なサーバーが残り続ける場合がある。前述の通り、Fleet Autoscaler は使用中(Allocated)の GameServer はスケールダウンから除外するため削減の対象にならないから明示的にshutdownしない限り永遠に残ってしまう。
まるで Zombie process のような状況なので、自分はゾンビサーバーと呼んでいる。 Agones の issue では Dangling Server とも呼ばれていた。 当然だがゾンビサーバーが残り続けると無駄なインフラコストの増加につながる。よってゾンビサーバーは適切にシャットダウンして落としていく必要がある。
そもそもゾンビサーバーが発生しないのが理想だが、現実はなかなかに難しい。 通信障害などの珍しいケースを踏んだときのみ発生するものも多く、そこまで考慮した実装を完璧に組むのは難易度が高い。
ひとつ暫定的な対処として、外部から定期的に Agones GameServer の状態をチェックして 明らかに zombie server となっていればシャットダウンする、といったJobを作る手がある。
また、 Allocate されたにも関わらず、しばらくプレイヤーが接続してこない…というイベントを検知して自発的にシャットダウンする実装を組むのもひとつの対策かもしれない。例としてGoでそのような実装を書いてみた。
func watchZombieServer(agones *sdk.SDK, firstPlayerConnected <-chan struct{}) { // waiting for allocated by agones for range time.Tick(1 * time.Second) { gs, err := agones.GameServer() if err != nil { log.Printf("failed to get GameServer: %+v", err) return } if gs.Status.State == string(v1.GameServerStateAllocated) { break } } log.Printf("The GameServer is allocated by Agones") select { case <-firstPlayerConnected: return case <-time.After(1 * time.Minute): log.Printf("The GameServer is allocated by Agones but no player has connected for %v (zombie server?)", timeout) agones.Shutdown() } }
- Pod Affinity の PreferredDuringSchedulingIgnoredDuringExecution による重み付けを利用して GameServer が多く乗っている Node を判定している https://github.com/googleforgames/agones/blob/86e678e7826d961d96a84a47fe72e398bddfb401/pkg/apis/agones/v1/gameserver.go#L762-L778↩
- 削除するGameServerを選ぶ際に、空いているNodeにあるGameServerが先になるようソートされる https://github.com/googleforgames/agones/blob/86e678e7826d961d96a84a47fe72e398bddfb401/pkg/gameserversets/controller.go#L480↩
- この挙動は最近改善された ので、将来的には気にしなくてよくなりそう↩